Monocular depth estimation (MDE) aims to predict scene depth from a single RGB image and plays a crucial role in 3D scene understanding. Recent advances in zero-shot MDE leverage normalized depth representations and distillation-based learning to improve generalization across diverse scenes. However, current depth normalization methods for distillation, relying on global normalization, can amplify noisy pseudo-labels, reducing distillation effectiveness. In this paper, we systematically analyze the impact of different depth normalization strategies on pseudo-label distillation. Based on our findings, we propose Cross-Context Distillation, which integrates global and local depth cues to enhance pseudo-label quality. Additionally, we introduce a multi-teacher distillation framework that leverages complementary strengths of different depth estimation models, leading to more robust and accurate depth predictions. Extensive experiments on benchmark datasets demonstrate that our approach significantly outperforms state-of-the-art methods, both quantitatively and qualitatively.
we introduce a novel distillation framework designed to leverage unlabeled images for training zero-shot Monocular Depth Estimation (MDE) models.
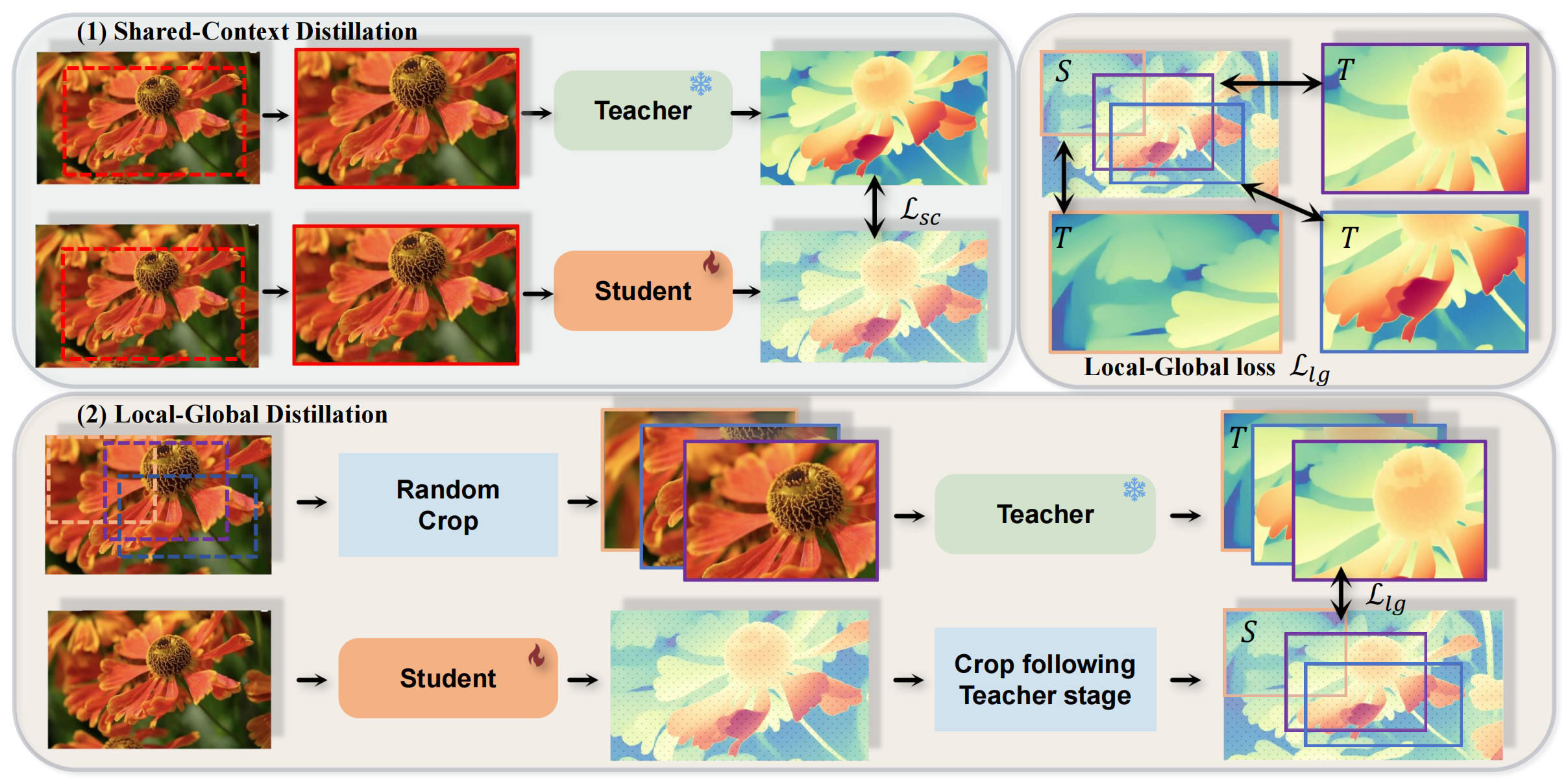
Overview of Cross-Context Distillation: Our method combines local and global depth information to enhance the student model’s predictions. It includes two scenarios: (1) Shared-Context Distillation, where both models use the same image for distillation; and (2) Local-Global Distillation, where the teacher predicts depth for overlapping patches while the student predicts the full image. The Local-Global loss (Top Right) ensures consistency between local and global predictions, enabling the student to learn both fine details and broad structures, improving accuracy and robustness.

Normalization Strategies: We compare four normalization strategies: Global Norm, Hybrid Norm, Local Norm, and No Norm. The figure visualizes how each strategy processes pixels within the normalization region (Norm. Area). The red dot represents any pixel within the region.

Different Inputs Lead to Different Pseudo Labels: Global Depth: The teacher model predicts depth using the entire image, and the local region's prediction is cropped from the output. Local Depth: The teacher model directly takes the cropped local region as input, resulting in more refined and detailed depth estimates for that area, capturing finer details compared to using the entire image.
Our model achieves SOTA performance across both indoor and outdoor scenes.
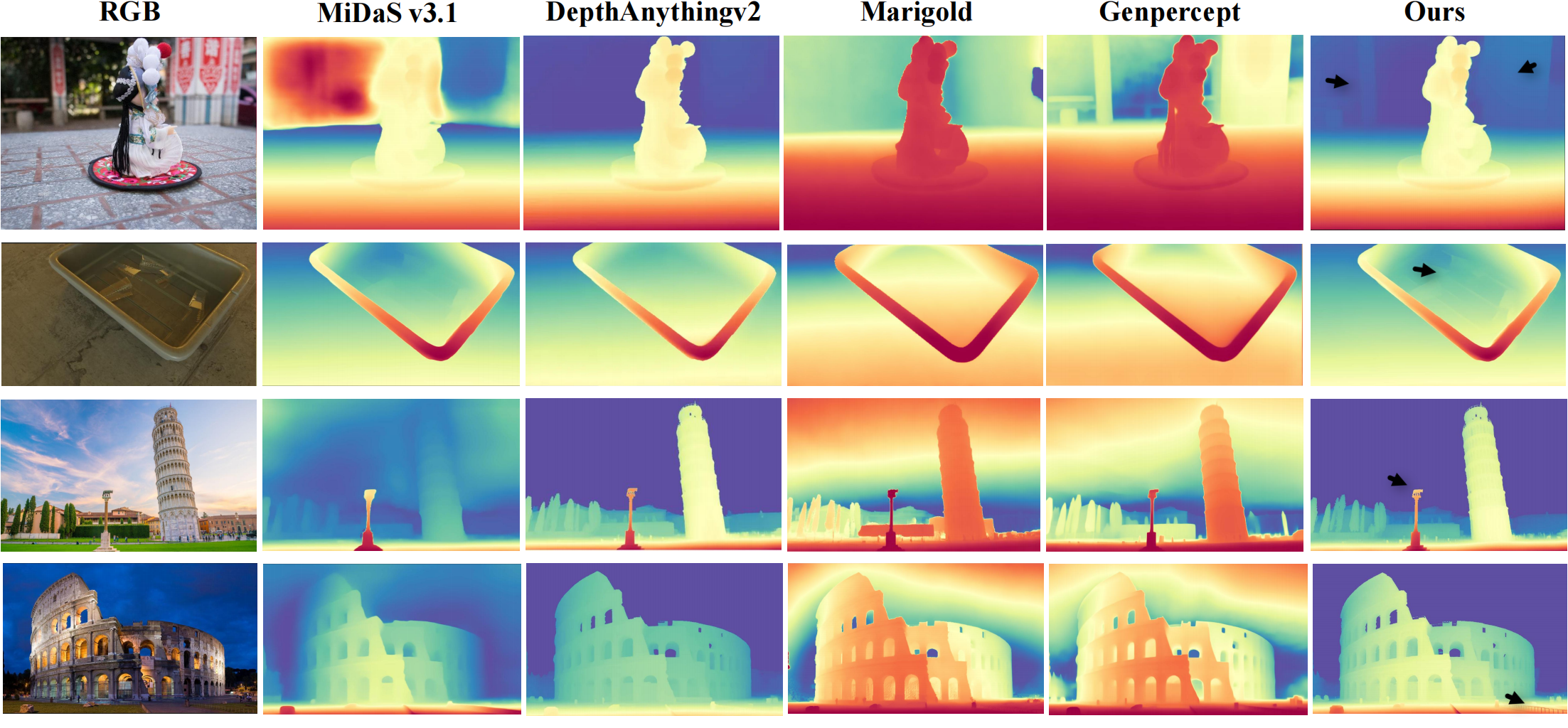
We present visual comparisons of depth predictions from our method ("Ours") alongside other classic depth estimators ("MiDaS v3.1", and models using DINOv2 or SD as priors ("DepthAnythingv2", "Marigold", "Genpercept"). Compared to state-of-the-art methods, the depth map produced by our model, particularly at the position indicated by the \textbf{black arrow}, exhibits finer granularity and more detailed depth estimation.
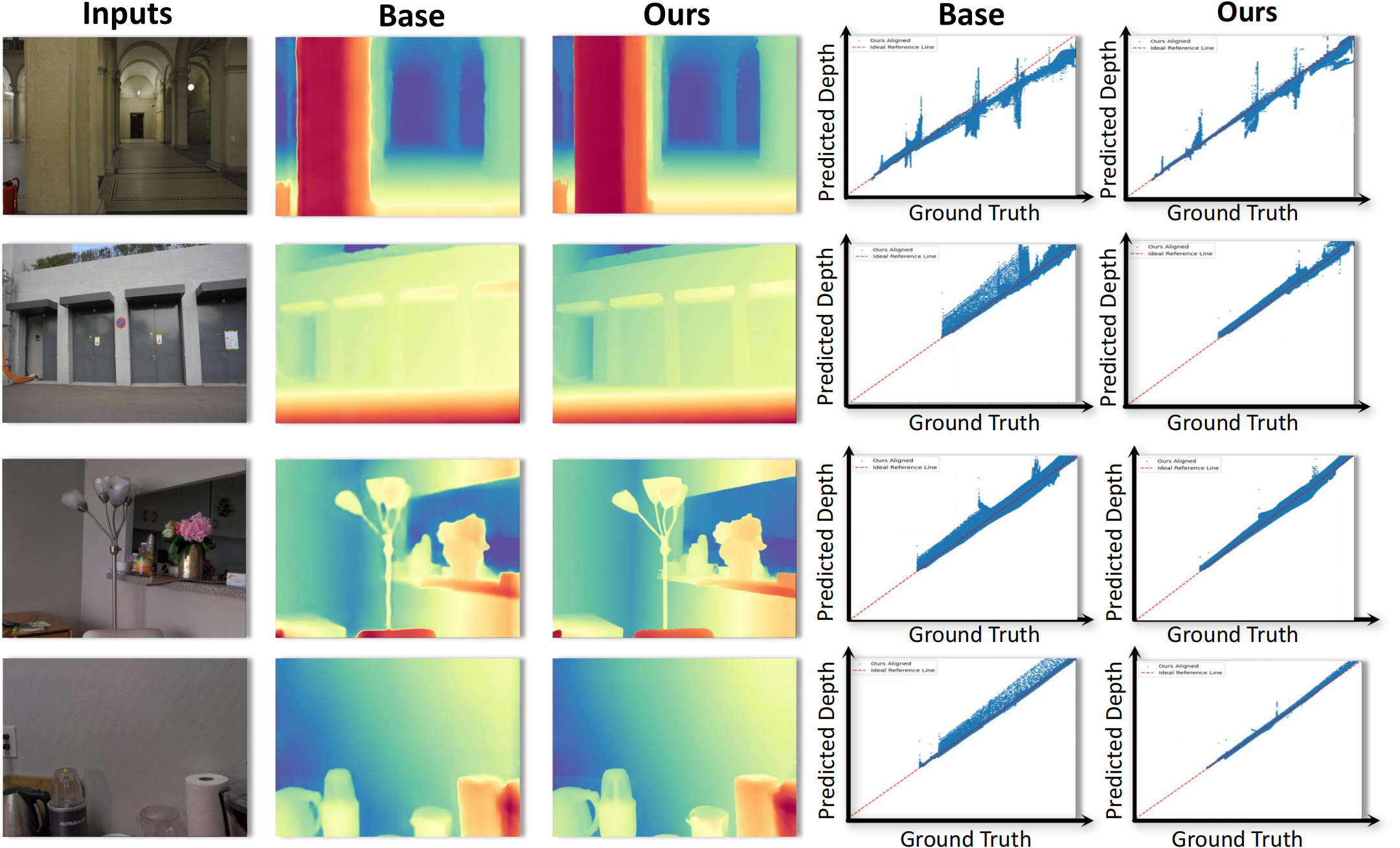
We compare our method with the baseline as the previous distillation method, which uses only global normalization. The red diagonal lines represent the ground truth, with results closer to the lines indicating better performance. Our method produces smoother surfaces, sharper edges, and more detailed depth maps.

Instead of just distilling classical depth models, we also apply distillation to generative models, aiming for the student model to capture their rich details.

We present point clouds generated from our model's predicted depth maps, aligned with geometry-preserving depth from MoGe. These visualizations demonstrate the effectiveness and practical applicability of our model in unconstrained, real-world scenarios.
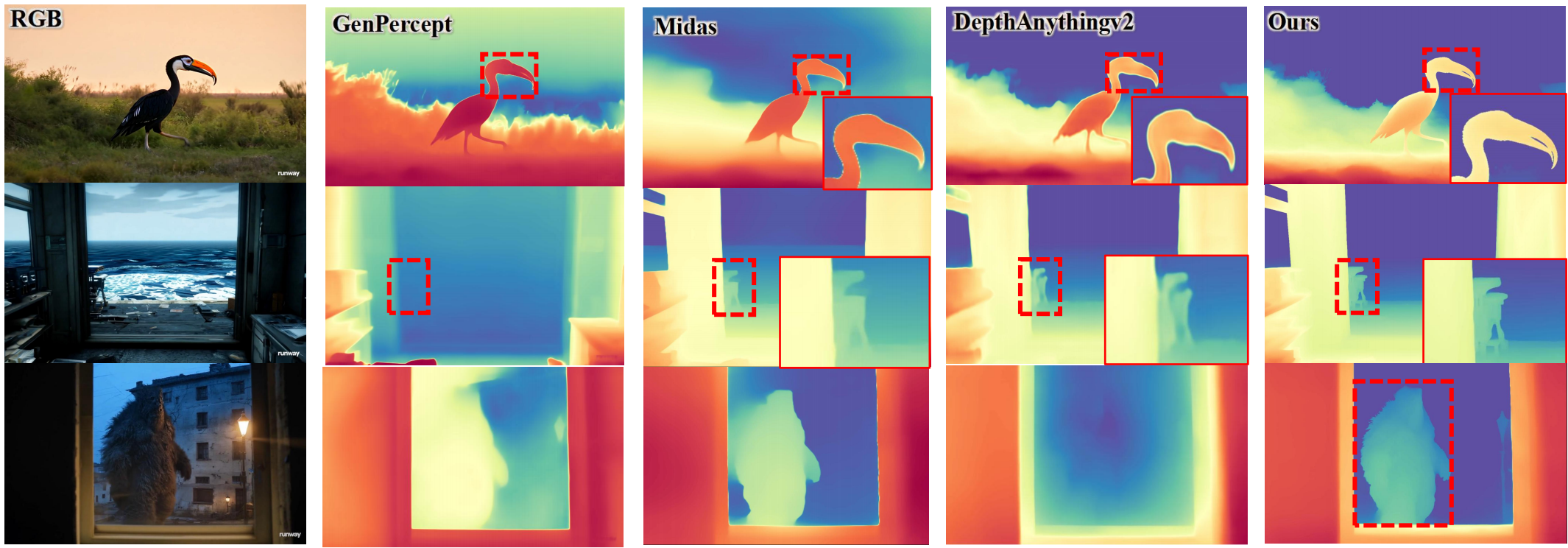
Our model, distilled from Genpercept and DepthAnythingv2, outperforms other methods by delivering more accurate depth details and exhibiting superior generalization for monocular depth estimation on in-the-wild images.
@article{he2025distill,
title = {Distill Any Depth: Distillation Creates a Stronger Monocular Depth Estimator},
author = {Xiankang He and Dongyan Guo and Hongji Li and Ruibo Li and Ying Cui and Chi Zhang},
year = {2025},
journal = {arXiv preprint arXiv: 2502.19204}
}

